
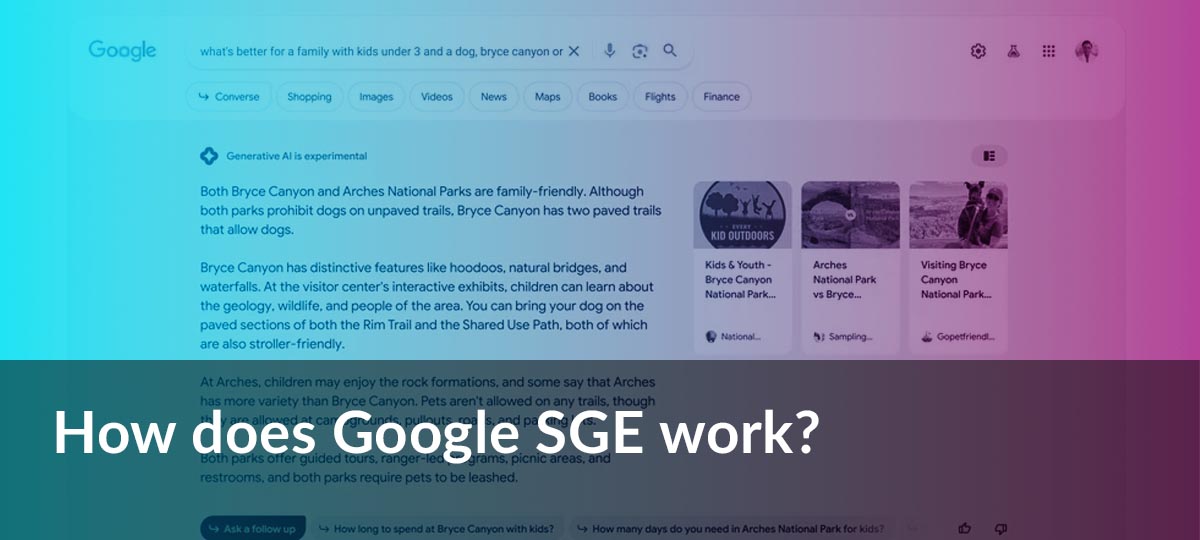
How does Google’s Search Generative Experience (SGE) work?
Google’s Search Generative Experience (SGE) transforms users’ search experience through generative AI. SGE enables users to ask more detailed questions in search, receive concise summaries of their queries, and have the option to engage in conversational follow-up queries. Currently, SGE is still in Beta and is being rolled out in multiple countries through Google Search Labs.
This article will look at how SGE is trained, focusing mainly on Google’s “Generative Summaries for Search Results” patent. This patent appears to describe the underpinning of SGE and provides insights into how it works.
Google’s SGE is trained on several large language models (LLMs) and has also been specifically trained for search-related tasks. For instance, identifying high-quality web results with associated sources that confirm the information provided in the output. These models work alongside Google’s core ranking systems to deliver helpful and reliable results that are relevant to search-user queries.
LLMs are machine learning (ML) models that excel at understanding and generating human language. LLMs are something that people have now become accustomed to interacting with on a day-to-day basis. Key examples include Chat GPT and Google’s Bard, which are underpinned by powerful LLMs.
LLMs are a form of Generative AI, meaning the AI model can generate something new. They can perform numerous tasks, including summarising, translating, and rendering text.
An LLM is made up of three key components: data, architecture (a neural network transformer) and training. The transformer architecture allows the model to handle data sequences, for example, lines of code or text sentences. Training is where the model learns to predict the next word in a sentence. The model will keep iterating and improving its predictions until it is reliable for generating sentences. Fine-tuning an LLM allows the model to excel at a specific task.
LLMs learn about patterns and language from the extensive data sets they are trained on. They can then create outputs for inputs. For instance, if we give it a string of text “can’t judge a book by its”, it will predict the next word and likely output “cover”.
SGE utilises a number of LLMs, including an advanced version of Multitask Unified Model (MUM), PaLM2, LaMDA and more. All of the LLMs are trained on vast amounts of data. Google uses multiple LLMs in SGE as it enables them to fine-tune the models to users’ unique needs, enhancing the search experience.
Google’s Multitask Unified Model (MUM) has been trained across 75 languages and has already been deployed on Google Search to improve the search experience. For instance, this model has been used to identify related topics in video content even when the topics aren’t directly mentioned.
PaLM 2 is a language model that excels in multilingualism, reasoning and coding. This is because it is trained heavily on multilingual text, large numbers of scientific pages containing mathematical expressions, and many publicly available source code datasets. Like all the others, this model is not limited to use in SGE. Google has also employed this LLM in Bard to enhance its language capabilities.
SGE is also employing Gemini to make it faster for users. Gemini was announced at the end of 2023 and is natively multimodal. Multimodal AI means it can understand and generate data across various modalities, including text, imagery and audio. Google noted they achieved a 40% reduction in latency for users in SGE.
The patent filed by Google in March 2023, named “Generative summaries for search results” was approved on the 26th of September 2023. It appears to be the patent underpinning Google’s SGE. This patent details an approach to using large language models (LLMs) to generate a natural language (NL) summary in response to a query. Meaning that the summaries are created in a way that is easy for a user to understand. The processes outlined in the patent are key to SGE. It covers not only how LLMs are utilised, but also where information could be pulled from to generate these NL summaries.
The patent also outlines how additional context will be considered for each query. This means there will be variability depending on the specific way a query is submitted or the context in which it’s asked. This explains why so many people researching and collecting data on SGE are finding so much variability in what shows up for them on different days or locations.
Additional information stated in the patent that could be utilised:
Google has stated that SGE may have knowledge gaps in certain areas and has, therefore, been designed only sometimes to produce a result if it concludes that it needs more knowledge to answer the query confidently.
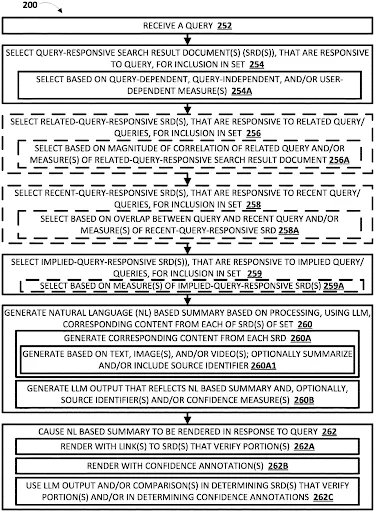
Additionally, the patent describes a system where the generated summaries will be evaluated based on the probability that they are both reliable and accurate. Confidence measures will be used to assess the natural language summaries to determine whether or not to produce a summary for a specific query. For instance, Figure 2 from the patent outlines the method and illustrates how confidence measures are implemented.
Furthermore, it is essential to recognise bias when it comes to generative AI. Google has acknowledged that SGE could produce biassed results. Google have stated the following:
“The data that SGE is trained on is based on high-quality web extracted data that can exhibit narrow representations of people or potentially negative contextual associations.” – Google
Google has implemented multiple measures to try to mitigate biased results. For instance, they use adversarial testing in SGE. Adversarial testing “involves proactively trying to “break” an application by providing it with data most likely to elicit problematic output.” (Google). This aims to identify bias and safety concerns in the model and use this information to improve the model.
The SGE Google experiment is an exciting time for generative AI and SEO. At Varn we are constantly monitoring and testing the updates to SGE to ensure our clients can appear within AI generated results. We have recently looked at the overlap between SGE and organic search results and we are continuing to collect and analyse data as SGE evolves.
If you have any questions about SGE, how it works and how it appears to be impacting SEO, please get in touch with the SEO Experts at Varn. We would love to hear from you.

Varn is an expert specialist SEO search marketing agency. Technical SEO * GEO + AI Visibility * Data Analytics * Digital PR * Content Marketing
You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More Information

